The AI hype cycle moves so fast that it can be hard to keep your bearings as new terms spring up overnight. MCP is one that I personally feel like a watershed moment for the GenAI technology. I want to provide a no-nonsense overview to help people wrap their minds around MCP as a concept.
High level: the what
MCP is an acronym for "Model Context Protocol". To break it down further:
- Model - refers to the LLM, this is intentionally generic
- Context - you've likely heard of this already, it's all the content either the application or your conversation provides as context for the LLM
- Protocol - how two parties communicate
Now, if I were going to be pedantic, I'd argue it's more of a convention than a true protocol (like HTTP or USB)... But insofar as it's intended to be the way models communicate with external sources to gain context, it is suitable. See, not too bad, right?
The specification's opening paragraph reads as follows:
Model Context Protocol (MCP) is an open protocol that enables seamless integration between LLM applications and external data sources and tools. Whether you’re building an AI-powered IDE, enhancing a chat interface, or creating custom AI workflows, MCP provides a standardized way to connect LLMs with the context they need.
High level: the why
LLMs are really amazing technical feats. You can view them in a way like compilers. They will compile all the data in their training set and provide weights for all the tokens in that training set.
Then, given some input the model will use those weights to create an output. This input and output can be text, image, video, anything really. The creation of the output is bound to the weights created during training. There is a lot of fancy math and great strides in computing that facilitate this being feasible but I'm not interested in a deep dive into the how of that. Instead I want to highlight two trade offs implicit to this process.
Problem one: Finite training data
The world is always changing, new information is being created every second. Your model's training data has a cutoff date. It will tell you, if you ask it.

If you ask a LLM, "What should I wear today?". How would you expect it to respond?
You might want it to factor in the weather in your specific location in its response. What if it could check your meeting schedule and use that info too? Without help, it can't do that. It doesn't have the context. Right now, you would have to include the weather forecast and your schedule into your prompt. Tomorrow, you'd have to do it again. The LLM doesn't know anything not in it's training data.
Problem two: They don't do anything
This may be controversial, and don't get me wrong, but LLMs can't actually do anything. They can only create outputs specifically for the weights for the data they've been trained on. They cannot effect change upon the world. They can answer your questions but they can't actually do anything with the answer. It would be up to the host application that integrated the LLM to provide this capability. This if often referred to as "Tools". Talk to an API, update a file, search the web; each application that sends user input to a LLM would need to create integrations for all the tools they would want to provide to their users. Compound that with the subtle differences and nuances between how different LLMs need to be called and how they respond and this quickly becomes a problem.
High level: the how & core MCP concepts
The specification is still evolving, but it has some substance and introduces various concepts and entities that are useful to know. Before we run through those, a high-level diagram will be useful to understand the relationships.
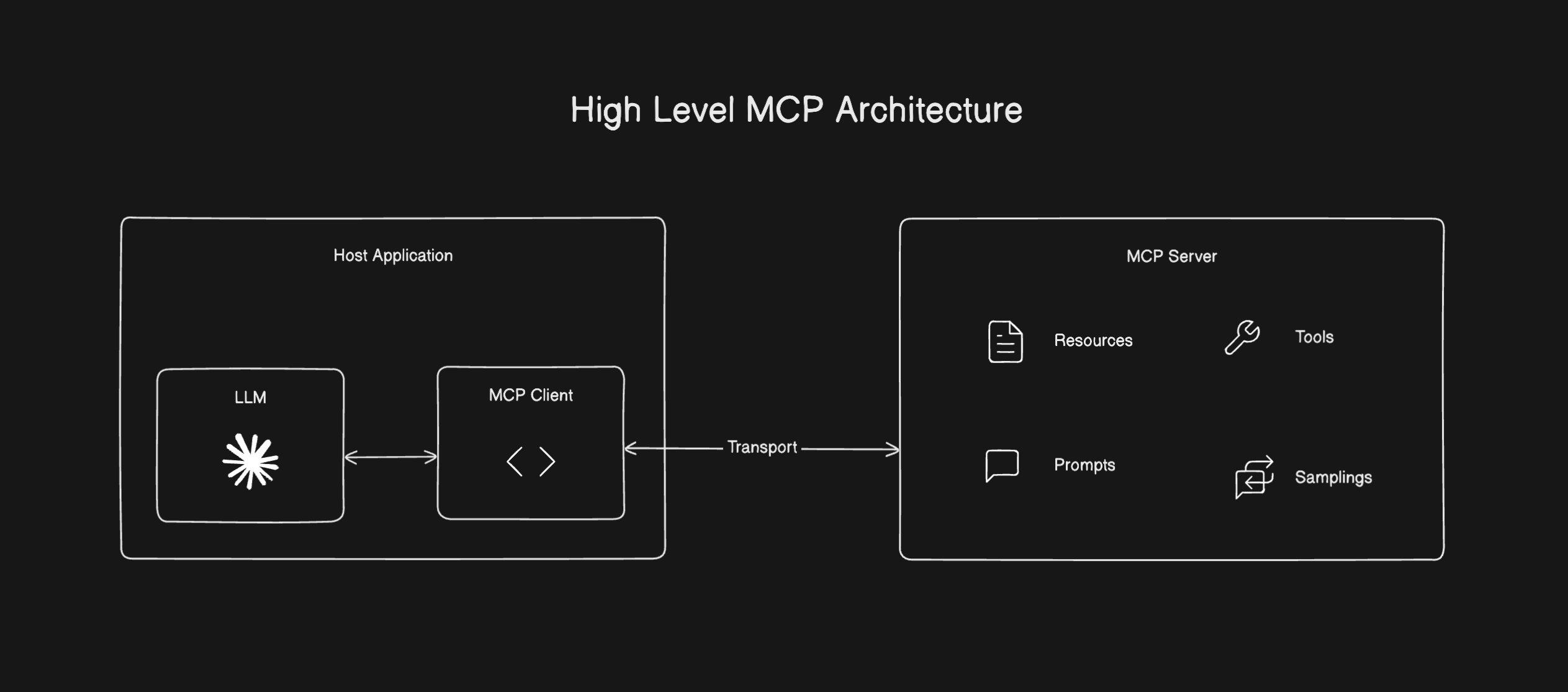
Architectural concepts
- Host application - this is the application the user interacts with. It will implement features that leverage an LLM. i.e. Claude Desktop, Cursor, Windsurf, VSCode, etc..
- MCP Client - The host application implements a client that maintains a 1:1 connection with a server
- MCP Server - These are external to the host application and provide context, tools, prompts, to the clients for usage by the host application.
- Transport - the spec supports a couple ways for how the MCP client and server communicate. Right now this is Standard Input/Output (stdio) for local servers or Server-sent events (SSE) for remote servers. In both cases, the JSON-RPC 2.0 format is used for messages. Note: SSE uses HTTP POST requests. While these are the two explicitly defined transport methods in the specification, there is also a way to define your own custom transport method should you need.
MCP Server Entities
- Resources - this is data and content that a server can expose to MCP clients. They are designed to be host-application controlled. i.e. file contents, database records, API responses, images, log files, etc..
- Prompts - servers can define reusable prompt templates and workflows that clients surface to their users. They are designed to be user-controlled and provide a powerful way to standardize inputs for LLM use.
- Tools - this is the most powerful primitive MCP servers provide in my opinion. They enable LLMs to interact with external systems, perform other work or actions. They're designed to be model-controlled, if an LLM thinks a tool will help it service a request it will use it.
- Samplings - this is a way that a MCP server can make a request to the Host application's LLM. It provides a powerful capability to servers, but so far I'm unaware of any MCP clients supporting this feature of the protocol.
Conclusions & current status
Ok, so with that quick overview, it should be clear why there is so much hype around MCPs. While I think the hype is warranted and that it enables powerful applications and unlocks interesting new experiences for users and organizations the reality is much more messy. Are you too late? Will this technology pan out?
Anthropic's Claude for Web client just this month added support for remote MCP servers in a feature they call "integrations". To go further, of all the applications implementing MCP clients - feature support is varied to say the least. This means a MCP server you make may have a different experience or incomplete behavior for users interacting with it from different clients, not ideal. It could be challenging to ensure a good or coherent experience for your users. For many big players not on this list, namely OpenAI, Google, & Meta, they have publicly committed to implementing MCP into their applications.
Secondly, while powerful and exciting for what it provides to applications, this does introduce an entirely new surface area for security vulnerabilities. Since these servers are getting data about you, your request, and relevant context and those servers can be doing whatever they want, that should give users a reason for healthy concern. This is generally referred to as 'tool poisoning attacks' and the community is exploring mitigation techniques. The protocol does support authorization via OAuth 2.1 but the initial specification didn't support auth at all. Since the spec is still evolving, it is unclear if it is ready for mass adoption or the correct choice for all use-cases.
The specification is very clear with great documentation, I recommend reading it thoroughly should you choose to go deeper here; it is very accessible. Additionally, while Anthropic initially created the specification, it is now considered an "open" effort. The modelcontextprotocol github org provides "first-party" sdks for many popular languages so that application devs can begin writing servers now. Current languages are Python, Typescript, Java, Kotlin, C#, & Swift.
My outstanding questions are really in the "rubber meets the road" area. How do these servers scale? How much does it cost to operate? How can you rate limit, or mitigate bad actors from misusing them? What's the story for observability and management of an entire suite of MCP servers look like? Etc..
Regardless of the unanswered questions, it is still very exciting and should really heat up in the next 6-12 months. There has already been an explosion of servers being published. I'm personally only using servers that I have created myself or severs that are open source and that I've reviewed the source code of.. But, I may be a bit more security conservative than you.
Regardless, the hype cycle induced FOMO may not be entirely warranted, but now is a really good time to get going on learning the technical skills required to build these out for yourself and organizations.
Additional Resources
- MCP Specification & documentation
- MCP Github Org
- MCP Typescript Quick Start
- Anthropic's announcement blog post
- Cloudflare MCP Docs
- Cloudflare's Guide to Build a Remote MCP Server
- MCP Security Notification: Tool Poisoning Attacks
Would you read a "build an MCP server how to" post? If there is enough interest, I will consider prioritizing the time to make that, let me know. Thanks for reading!